
Data decomposition involves breaking data into its constituent parts, in the hope that patterns become easier to see. There are two broad types of data decomposition: theory-based decompositions, which rely on the analyst to use their judgment to perform the decomposition, and algorithmic decompositions, which use math to automatically decompose the data. Decompositions are useful both to find insights and as an input into additional analyses (e.g., forecasting).
Theory-based decompositions
There is no standard set of theoretical decompositions. Pretty much any conceptual framework can be used to decompose data. However, the following decompositions are widely used:
- Financial decompositions
- Geographical and product decompositions
- Frequency versus penetration
- Seasonal decompositions
Financial decompositions
There are numerous financial decompositions. The most widely known is perhaps Profit = Revenue - Cost. Each revenue and cost can in turn be decomposed. For example:
Revenue = # Customers × Average units per customer × Average price per unit
or
Revenue = Market Size in Units × Market Share in Units × Average price per unit
Geographical and product decompositions
Another pair of standard decomposition is to split profit or revenue up according to geography and product lines.
Frequency versus penetration
In data where the same event occurs again and again, such as media usage and purchasing, it is often helpful to use the decomposition:
Observed data = Penetration × Frequency
The table below on the left shows the average proportion of episodes viewed of some TV programs. We can decompose this average proportion into the % of people that watched (penetration) and the average proportion watched by those that watched (frequency). When we look at the overall average proportions we see that The Mandalorian and Stranger Things are clearly in first and second place. This is true for both the penetration data (the middle column) and the frequency data (the right column). It is common that such data is highly correlated; so common that there is even a term to describe it: double jeopardy.
However, note that the difference in the penetration data (the middle column) is relatively small, and the key thing that is driving the differences, in this case, is the data in the rightmost column, with people that watch The Mandalorian and Stranger Things watching them twice as much as the other programs are watched.
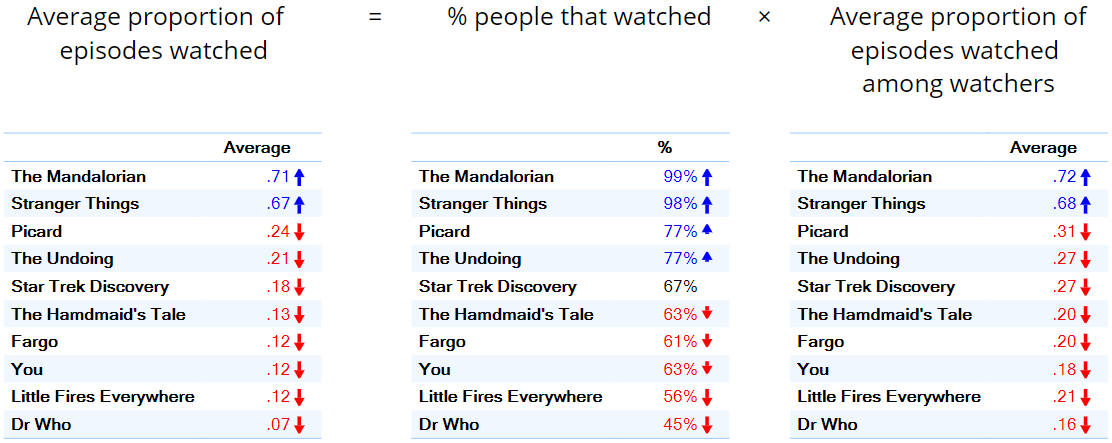
For more information about double jeopardy, see Repeat-buying: Theory and Applications, Andrew C. Ehrenberg (1972).
Seasonal decompositions
A seasonal decomposition assumes that a key feature of the data is that some behavior recurs in sync with the seasons of the year, typically defined based on months or quarters. The two most common seasonal decompositions are:
The additive seasonal decomposition: Observed data = Trend + Season + Random
and
The multiplicative seasonal decomposition: Observed data = Trend × Season × Random
The top chart below - Original Data - shows beer production in Australia by quarter. We can see clearly from this chart that there is a very regular pattern in the data which, whereby every quarter there is a peak at the October quarter, and then a trough until the next October quarter. This is an example of seasonality. Typically the main focus when performing a seasonal decomposition is to focus on the Trend component, as it is easier to see patterns when the noise and seasonal variation are removed. In this example, we can see that Australian beer production grew up to the mid-1970s and started declining around 1990.
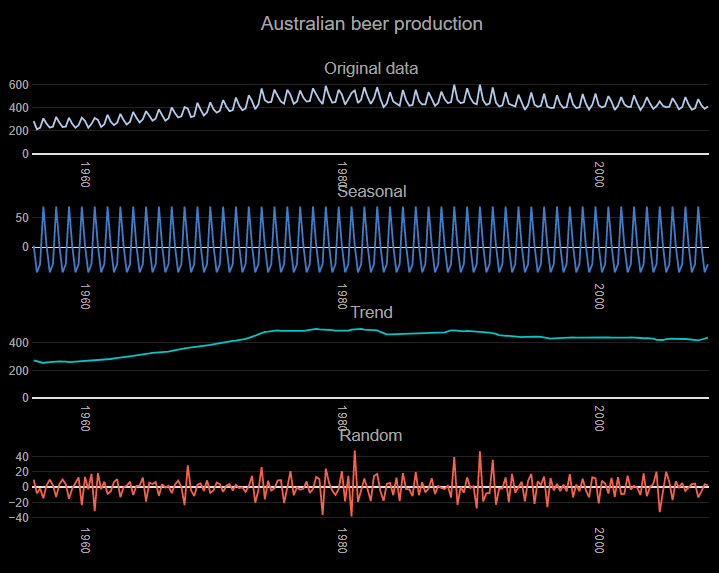
Algorithmic decompositions
With a theory-based decomposition, the analyst decides how to decompose the data. With an algorithmic decomposition, software automatically finds the best decomposition, where the best is typically the decomposition that maximizes the variance explained of a small part of the decomposition.
Four widely used algorithmic decompositions:
- Automated time series models.
- Correspondence analysis.
- Factor analysis / principal component analysis
- Tree-based models.
Automated time series models
In the example above of seasonal decomposition, the decomposition was performed by making the assumption that seasonality was a key component. An alternative approach is to use algorithms that hunt through the patterns in the time series data and find the decomposition that best explains the data. Such algorithms can automatically find seasonal decompositions if the exist.
Correspondence analysis
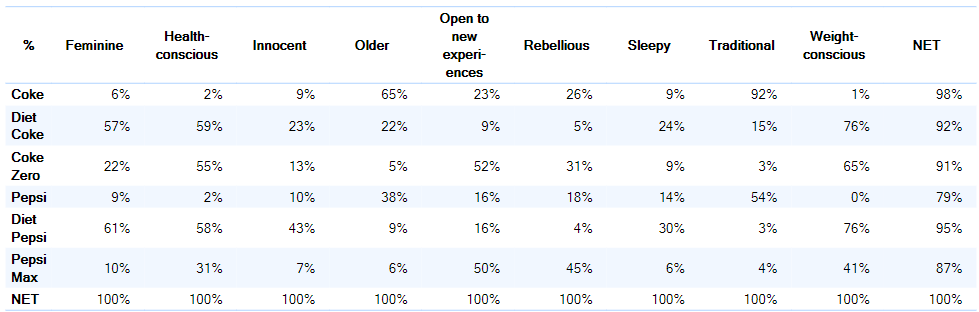
Consider the table above. It has a lot of numbers. It's hard to find a pattern. One of the reasons that it is hard to find a pattern is that, excluding the net column, it contains 9 dimensions (i.e., 9 columns). If we were just to look at the first two, say as a scatterplot, we would likely be able to more quickly extract some meaning, but then we would have ignored 7 of the dimensions. Correspondence analysis is used to find the best two dimensions that explain the data, and plots these. An example of the output is below. For example, we can see that:
- Diet Pepsi and Diet Coke are very similar to each other.
- Diet Pepsi and Diet Coke are most strongly associated with health and weight-consciousness.
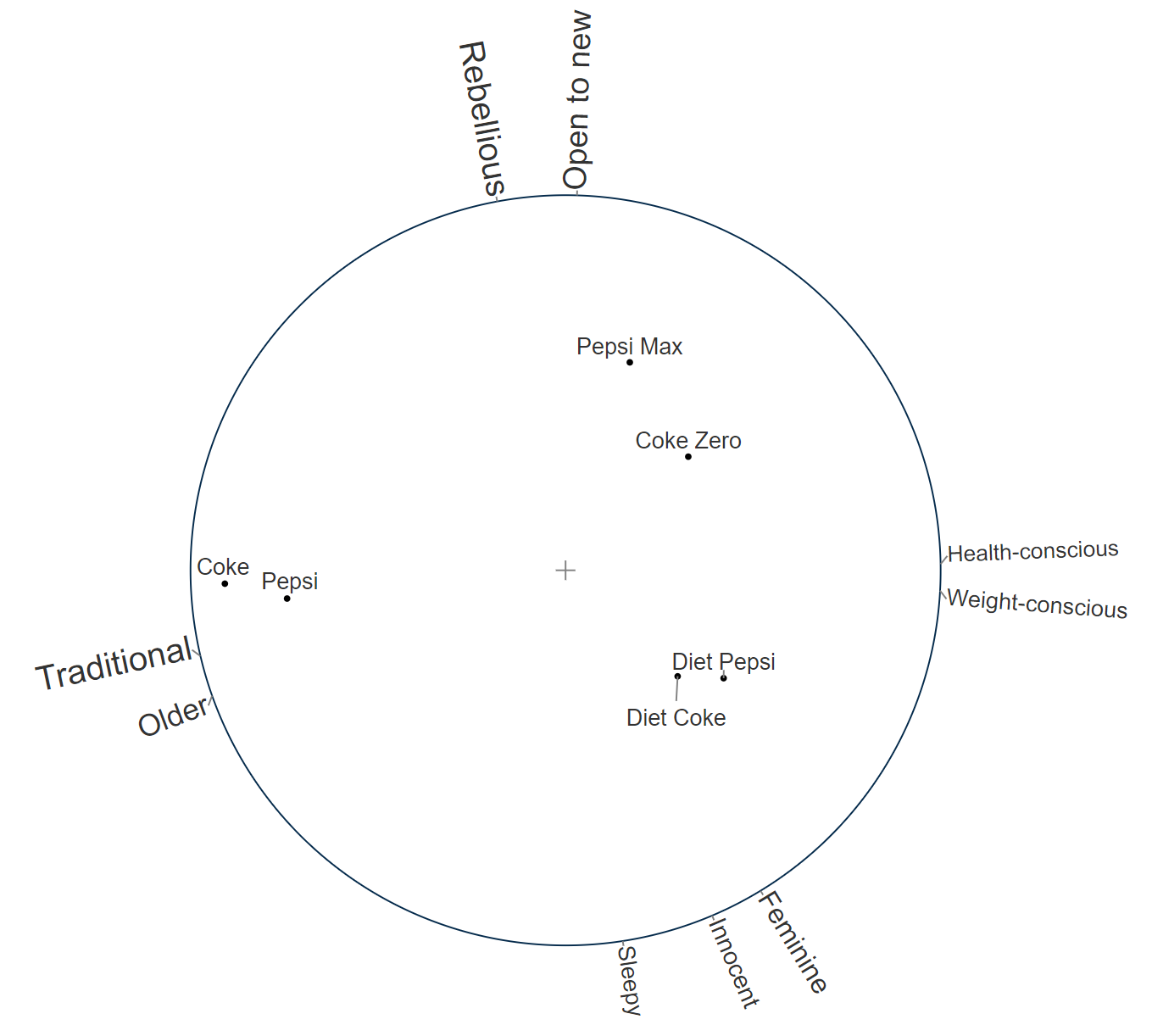
Factor analysis / principal component analysis
Factor analysis, and the almost identical principal component analysis, perform a very similar role to correspondence analysis, except that whereas correspondence analysis is typically applied to the analysis of categorical data, factor analysis is mainly applied to the analysis of numeric data.
Tree-based models
The section on tree-based models discussed how geography and product were common decompositions. It is not unusual that there are many possible ways of decomposing data, and there is a need to choose or combine the best of these. This is what tree-baed models, such as CART and CHAID do.
Comments
0 comments
Please sign in to leave a comment.