
Sorting involves reordering the rows and/or columns of table or visualization in a particular order. When sorting, we need to work out a principle for ordering the data, deal with exceptions, and decide whether to use consistent or automatic sorting.
Choice of order
There are six main ways of ordering the row or column categories. From most to least useful they are:
- Natural ordering of the categories. For example, it is typically better to order age categories in ascending order than any other way.
- Importance of the categories. For example, if showing data about different brands, ordering the brands based on market share is usually appropriate.
- By the order of the values associated with the categories (highest to lowest, or lowest to highest). When the table contains multiple columns, it is usually appropriate to sort based on the total or average of the columns.
- The alphabetic order of the categories. This is most useful if there are a large number of categories and the main use of the table is as a reference rather than as something to be explored to provide insight.
- The order in which the categories were collected (e.g., the order in the questionnaire).
- The order with which the categories are stored in the database.
By default, most software will automatically order the data based on the order in which the categories are stored in the database. In some situations, this is not a problem. For example, typically ordinal data, such as age categories and attitudes, are stored in their natural order. However, often with unordered categories, the order with which the data is stored is determined by how the data was collected or by alphabet, making it desirable to reorder the data
As an example, consider the two tables below. The one on the left is sorted alphabetically. The one on the right from highest to lowest. It is much faster to draw conclusions from the table on the right, which has been sorted based on values in descending order (highest to lowest). Furthermore, if we know the data is sorted, we can draw conclusions from the table on the right that cannot be obtained from the one on the left (e.g., The Mandalorian is the most popular show and Dr Who the least popular).

Dealing with exceptions
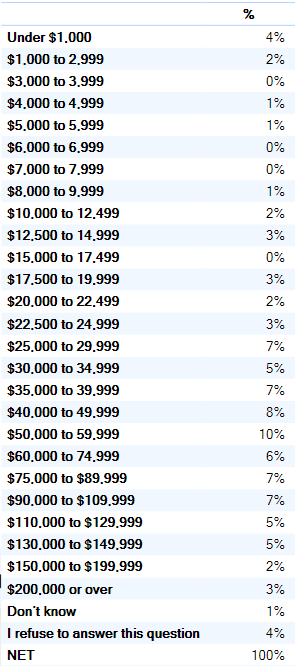
The table below is income data, which is shown in its natural ordering. Note that the Don't know and I refuse to answer this question options are shown at the bottom. Similarly, if an Others category existed it would also typically be shown at the bottom. It is good practice to always have such categories ordered at the bottom, regardless of whether ordering by alphabetic, value, or some other criteria. This is because any patterns relating to such exception categories tend to be different from the other patterns in the data, so if these exception categories are included in the ordering all the patterns become harder to see.
Consistent versus automatic sorting
When sorting tables and visualizations a choice needs to be made between:
- Sorting each table automatically (e.g., from highest to lowest).
- Using a consistent ordering across all the tables.
Which is best tends to relate to the goals of the reporting. If the reporting is a compendium of some sort, where people will only look at one or two tables, it is often helpful to sort each table independently. However, if the intent is that somebody will read through the whole report and attempt to understand the data as a whole, it is usually appropriate to find a single way of ordering each bit of data, and use that consistently throughout the table. For example, if ordering a list of brands, it is usually desirable to show the same ordering throughout the report, as this allows:
- People to skim through and pick out results relating to a particular brand (e.g., if Coca-Cola is always in row 1, it is easy to find the data without much effort).
- Discrepancies to become clearer. For example, if bar charts are used to show results, and on one page the bar for the first category is smaller than that for the second, this discrepancy becomes easy to spot.
Comments
0 comments
Please sign in to leave a comment.