
When analyzing data, data reduction refers to the process of reducing the quantity of data, by getting rid of interesting data, so that only the interesting data remains. Key techniques for reducing the amount of data are to:
- Delete insufficiently-rigorous analyses.
- Delete uninteresting analyses.
- Remove clutter.
- Merge similar things.
- Replace data with summary statistics.
- Reorder.
- Change the scale.
- Decompose.
- "Common sense".
These steps can be conducted in any different order, and often again and again in the course of an analysis
Why data reduction is useful
There are two useful analogies for understanding data reduction. This first comes from Michelangelo. When creating his great statue, David, he was asked by the pope of the day how he had created David, to which he replied "It's simple. I just remove everything that's not David." This is the same basic concept that needs to be used when performing analysis: keep deleting data that is not interesting to stakeholders, and you are left with the story in the data.
The second analogy is the idea that we throw away data with the goal of concentrating results, so they are stronger.
These two analogies emphasize the two ways that data reduction works:
- By reducing the quantity of data we make it easier to see the patterns.
- By changing the data, we make it easier to see patterns.
The next section discusses the first of the data reduction techniques: deleting insufficiently-rigorous results.
Delete insufficiently-rigorous results
Many analyses are not rigorous enough to be relied upon. Deleting such analyses is a good place to start when looking for ways to reduce data.
Significance Testing
Often many analyses are purely exploratory in nature. For example, it is common to identify key pieces of data and then see how they relate to every other piece of data. As an example, in a study investigating the appeal for the iLock, the key question relates to how likely people were to say they would purchase the iLock (purchase intent), and exploratory tables were created showing the relationship between purchase intent and all the other data in the survey.
Such analyses are purely speculative in nature. There is no particular theory. Rather, you run the analyses just hoping that you may spot something useful.
With such exploratory analyses, the absence of any statistically significant findings is often sufficient grounds to conclude the result is not worth thinking further about. One of the outputs of this exploratory analysis is shown below. The table shows purchase intent by how long people took to complete the questionnaire. The absence of any arrows on this table indicates the differences are not statistically significant, telling us that there is no point in spending a second more in trying to extra meaning from the analysis. It can just be discarded without further consideration.

With more modern tools, it is practical to specify a large number of possible tables and have them automatically deleted based on statistical significance, without ever reading any of them.
Thinking through causality
Significance testing is ultimately making a conclusion about causality - what causes what. The conclusion is that sampling error - the noise caused by the random selection of data - is the most likely explanation for the patterns in the data, rather than there being a more interesting explanation. We conduct significance tests because if the pattern is caused by sampling error, it means that the pattern is not very interesting. There are, sadly, many other interesting causes of the pattern as well. For example, patterns may reflect response biases - the different ways that people like to answer questions - rather than reflecting important differences in consumer behavior.
We can check the rigor of an analysis by a series of common-sense checks: assessing it feels likely to be true, is consistent with other data and theories, can is not consistent with alternative plausible explanations.
For more information, see Using Common Sense to Test Conclusions.
Delete uninteresting analyses

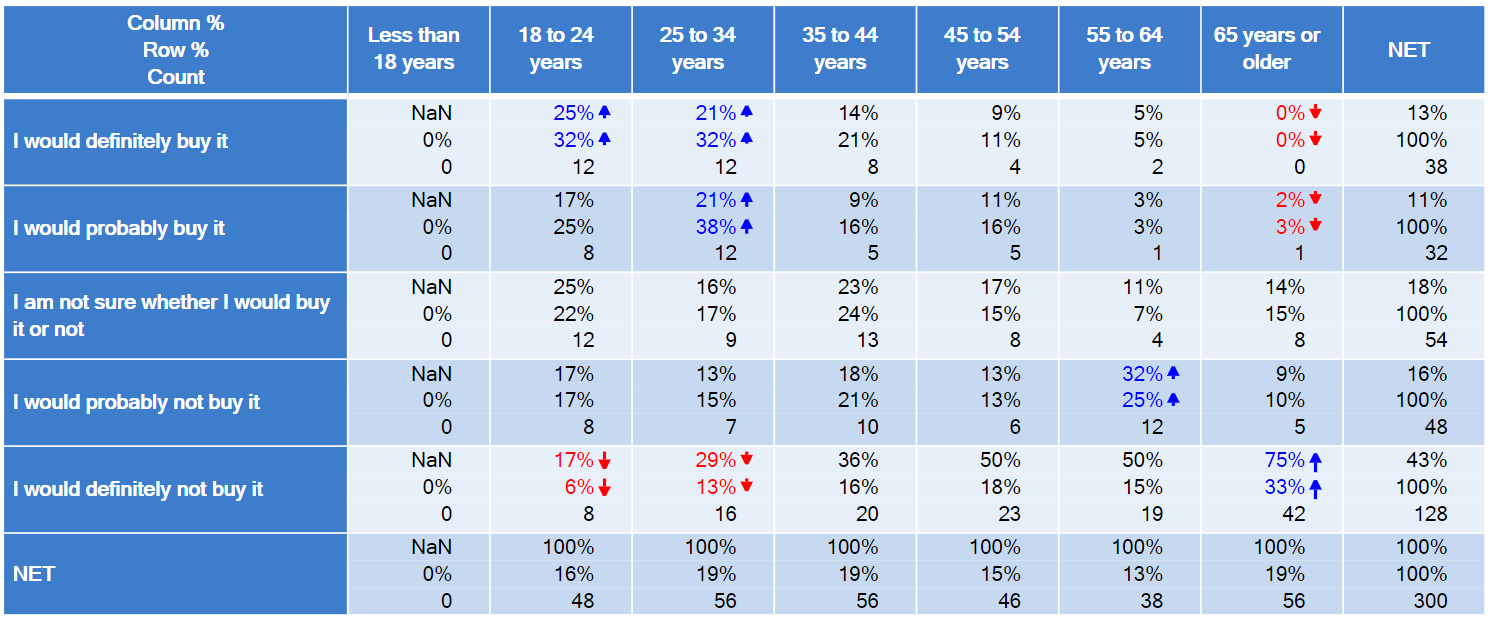
The table below shows purchase intent by gender. The significance tests indicate that the females were more likely to say I would definitely not buy it than the males.
If performing an exploratory analysis, we would look at this output and conclude that it is just not interesting. A difference in the I would definitely buy score or the top 2 box score (I would definitely buy it + I would probably buy it) would be interesting, as then there are implications in terms of which genders should be targeted. But, knowing that females were a bit more likely to say I would probably not buy it and a bit less likely to say I would definitely not buy it (as appears to be the case), is just not interesting. The appropriate next step is to discard the analysis and look at something else.

Remove clutter
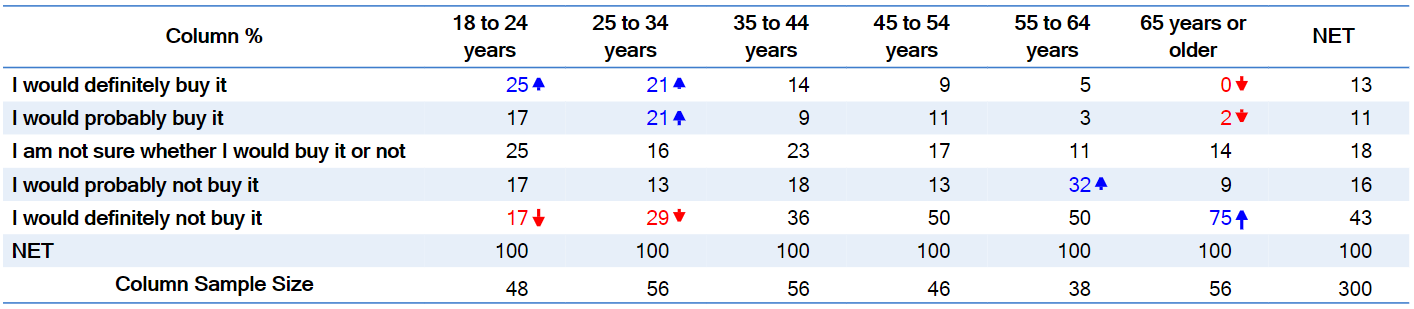
In the early days of data analysis, it routinely took days or even weeks for analyses to be run, due to both the slowness of the computers and the backlog of work by the small number of people that could run the software. This slowness meant that it became normal to request analyses that contained lots of different views of the data, as you wanted to make sure that you did not have to ask for further analyses. The result was that most market researchers would request tables showing Column %, Row %, and counts (referred to as n in some software). An example is shown below.
We can improve on this table by removing the clutter:
- Getting rid of the row %
- Replacing the count statistic in every cell with a column sample size
- Removing the first column, as it contains no data
- Removing the redundant % sign next to each table
- Use lighter background colors, so that the row and column color doesn't distract us from the data.
The resulting table is shown below. Is it perfect? No. But, it is a substantial improvement in terms of data reduction. The table above contains 144 numbers and 145 percentage (%) signs. The table below contains 49 numbers and 1 percentage sign. That's a substantial reduction in data without any loss in information.
The concept of removing clutter is a very general one, which finds application throughout data analysis and presentation, such as the recommendation to remove all clip art (chart junk) from visualizations and to use presentations with plain white backgrounds.
Combine similar things
Merging similar things is another way of reducing the amount of data. Consider the table above. The data in the first two columns tell broadly the same story. Similarly, the results in the 25 to 44 years and 45 to 54 years are also broadly similar. While there are some larger differences between the last two categories, in terms of their core implication, they are the same (older people are unlikely to buy the iLock). Consequently, we can substantially reduce the amount of data by merging these columns, as shown in the table below.
We combine things when they are broadly similar, even if not identical. There is always a degree of subjectivity in this process. Some information is lost, but if we make good decisions the information loss is more than compensated for by the data reduction.
There are a variety of ways of merging categories, including:
- Using judgment, as in the example above.
- Algorithms for merging categories, such as CART and Mixed-Mode Trees.
- Algorithms for merging variables, such as factor analysis.
- Algorithms for merging cases, such as cluster analysis and latent class analysis.
Replace data with summary statistics
When we use the average (mean) to summarize raw data, we are substituting a single number, the average, in place of the original raw data. As with most forms of data reduction, we lose some information (the variability between people) but hopefully what is lost is largely noise, allowing us to focus on the main story, which is communicated by the average.

As an example, consider needing to explore the relationship between the viewing of 10 different TV programs, where for each program people had chosen one of the following six categories to indicate how many episodes they had watched:
- None
- Started one
- 25%
- 50%
- 75%
- All
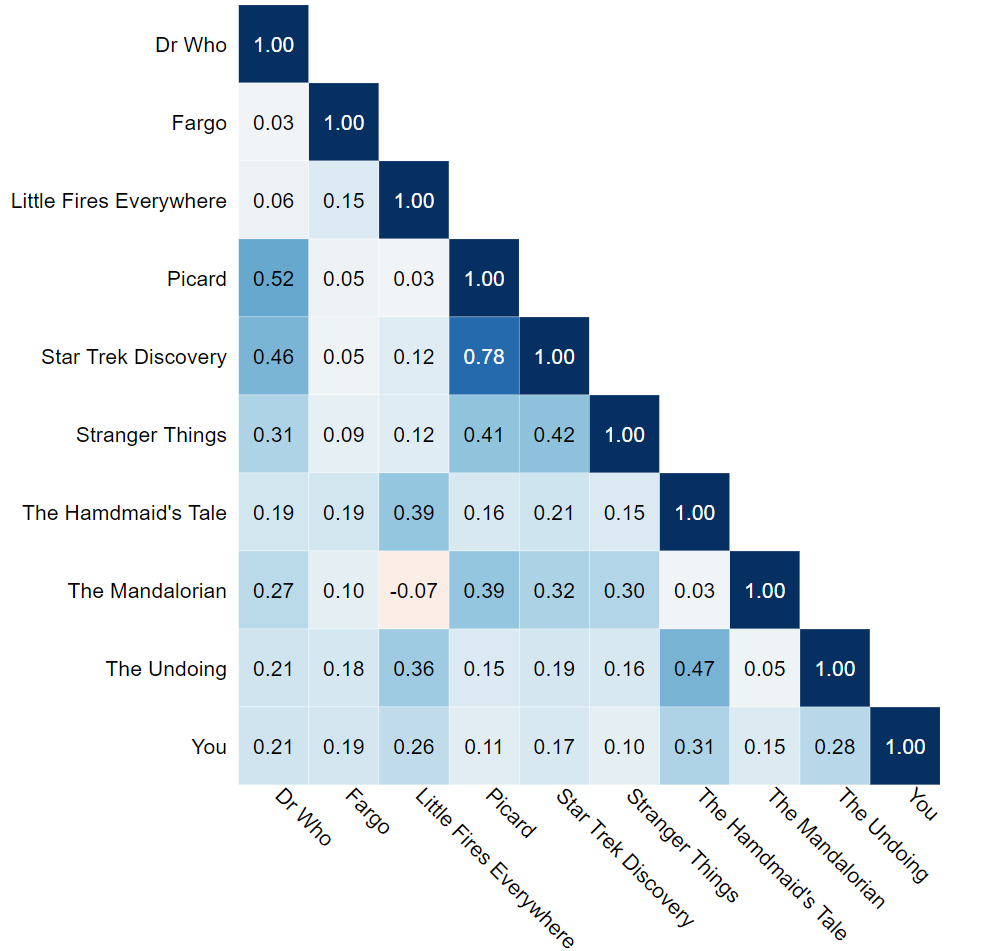
The table below shows a crosstab of all this information (note the scrollbars - it is too big to view it all at once). It is s very, very, big crosstab. With a lot of effort and you could find the key patterns in it.
By contrast, the table below shows the same data, but rather than showing each category by each other category, the data has been treated as being numeric, and correlations computed between the viewing data, reducing the massive table above, to a table where we only need to look at the 45 numbers. The way we read these numbers is that the further from 0, the stronger the pattern, with positive numbers indicating that people who watched one show were more likely to watch the other, and negative indicating the opposite.
For more information about these topics, see:
Reorder
Changing the order of rows and columns in tables is a particularly effective way of making the patterns in data easier to see. There are two basic approaches. The simplest is to sort data (e.g., from highest to lowest). For tables containing multiple rows and columns, an alternative approach is to diagonalize the table, which means that the rows and columns are reordered so that diagonal patterns appear in the tale. The best way to appreciate what this means is to contrast the heatmap below, which has been diagonalized, with the earlier heatmap which was in alphabetic order.
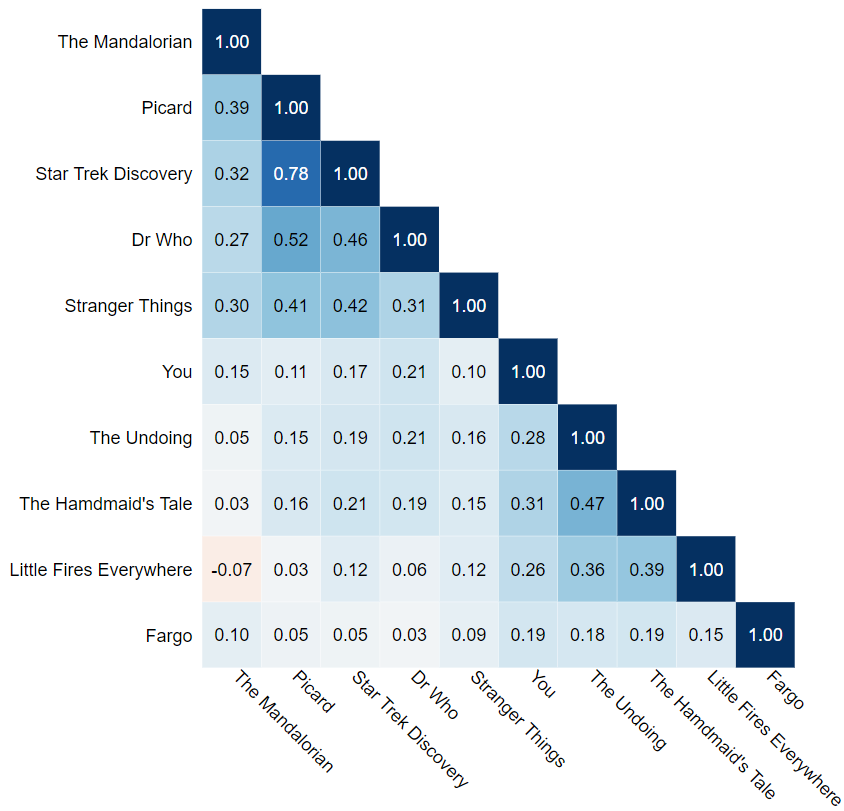
The point of changing the order of data is that it makes patterns in the data easier to see. In the diagonalized heatmap shown here, we can readily see, for example, that viewing of the first five shows are comparatively more correlated than with the other shows.
For more information about these topics, see:
Change the scale of numeric data
Consider the numbers $2,000, $4,000, $6,000, and $20,000. If we change the scale of the data, by dividing by $1,000, we are left with 1, 2, 3, and 10. These numbers are easier for our brains to process.
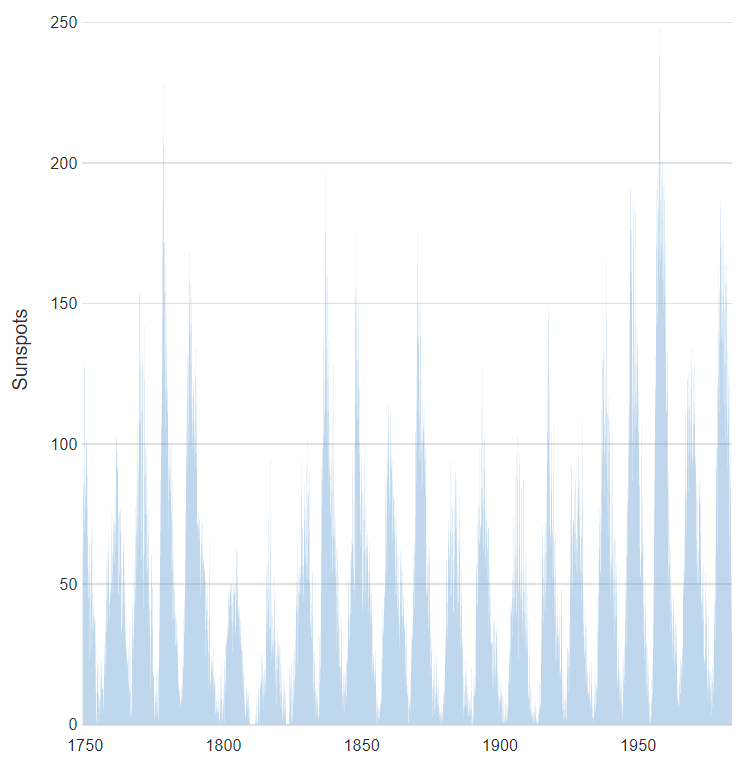
A useful way of understanding the effect of scale is a classic data visualization of how monthly sunspot data. Look at the visualization below. What patterns can you see in this data? The most obvious pattern is that there seems to be an approximately 11-year cycle.
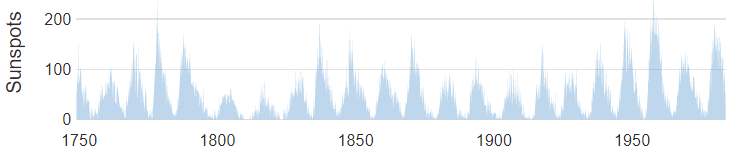
The visualization below is identical, except that the size of the y-axis has been massively compressed (i.e., the visual scale has been reduced) Intuitively you might expect that the smaller visualization below will show less information, but it actually shows more. In particular, note how we can see in each 11-year cycle, that the number of sunspots rapidly grows to its maximum, and then slowly declines.
Returning to the earlier case study of purchase intent for the iLock, the table below on the left shows the average purchase intent, when the product was shown with No price and when shown at $199. You could be forgiven for thinking that this table shows that the priced concept is more appealing than the unpriced.

However, the table on the left is showing the average purchase intent, where people that have said I would definitely buy it have given a score of 1, I would probably buy it a score of 2, and so on, so the correct reading is that the lower the average the higher the purchase intent.
An alternative scale for showing purchase intent data is to assign a value of 100 to the first category, indicating that based on what people have said, 100% of the people that said they will "definitely buy" will buy it, 75 for the probably buy category, 20 for I am not sure, and 0 for the remaining categories. By changing the scale of the data to this probability coding, we get the table on the right, which is much better than the one on the left in that:
- High values correspond to higher repurchase intent.
- The values shown correspond to something that can be explained. An average of 3.7 on a scale where 1 means definitely buy and 5 means definitely not buy is very hard to understand. By contrast, the table on the right is estimating probabilities, which have a clear commercial interpretation (e.g., if 32.2% of people say they will buy, and this is accurate, then the product will be purchased by approximately 32.2% of the market).
Decompose
Data decomposition involves breaking the data into its underlying elements. For example:
- A standard decomposition in financial analysis is profit = revenue - cost.
- In analyzing time series data, a standard decomposition is observed data = trend + seasonal component + noise.
The way that decomposing helps is that often the insights in the data are more obvious when some of the data is removed. For example, if comparing companies based on profit alone, it may be hard to see patterns, but when performing the comparisons based on revenue or cost, insights may be more obvious.
For more information, see Data Decompositions.
"Common sense"

Perhaps the most powerful way of reducing data is to apply common sense, to work out which data is revealing results that are unlikely to be very useful. In practice, this amounts to three key checks:
- Does a result seem fish?
- Is the result consistent with other data and theories?
- Are there alternative plausible explanations (APEs) that cannot be ruled out?
For more information, see Using Common Sense to Test Conclusions.
Comments
0 comments
Please sign in to leave a comment.