
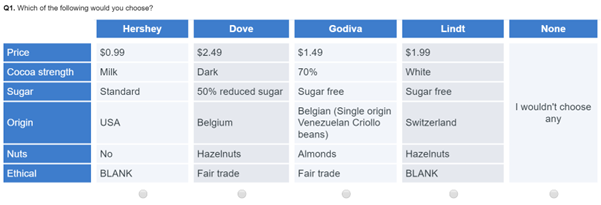
A labeled choice task/question assigns a name to each of the alternatives. Most commonly, these are brand names, as in the example below.
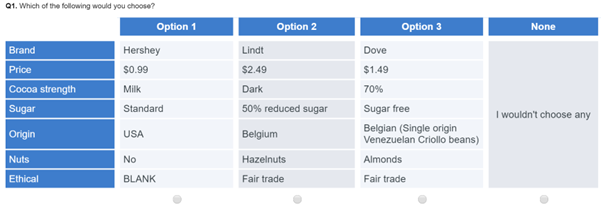
By contrast, an unlabeled task either has no name or has a generic name, as in the example below.
The decision about whether to use labeled or unlabeled alternatives comes down to:
- Whether alternative-specific attributes exist. That is, are there some attributes that are only applicable to some alternatives? For example, if conducting a study of the car market, where one of the brands is electric, then typically you will need to have alternative-specific attributes for that brand. This is discussed in more detail in Alternative-Specific Designs.
- Whether an availability design is required (see Availability Designs).
- Whether the goal of the study is to focus on understanding the differences between people (segmentation), or, to produce forecasts. If the goal is to produce forecasts, then it is often advisable to use labeled alternatives, where they are labeled according to a label attribute such as brand, which connotes intangible features. Where this is not done, the consequence is that the same level can appear multiple times in a question (e.g., two alternatives showing Coke and none showing Pepsi), which:
- Leads to potential confounding of estimates of the utility of the label attribute’s levels. For example, if two Coke alternatives appear twice, then all else being equal we expect each of those alternatives to be less appealing than on their own, which causes either the utility of Coke to be under-estimated or if such under-estimations cancel out across all the attributes, an increase in the overall variance (error) of the model.
- Can appear unrealistic in some circumstances, reducing the quality of the data.
Comments
0 comments
Please sign in to leave a comment.