
However, data quality problems can cause the conclusions of the Kano model to be misleading:
A worked example is presented at the end of the article.
Flatlining
Consider the situation where a user has flatlined, giving the same answer for all features. The resulting data will lead to incorrect conclusions regardless of which of the analysis methods is used.
If using categorization analysis, the size of the Questionable and Indifferent categories will be inflated, potentially causing some features to be placed in the wrong category.
If using satisfaction coefficients or continuous scale analysis, the position of the features on the scatterplots will systematically be biased due to the flatlining. For example, if people have flatlined and chosen Like it on both scales, then the resulting analysis will shift all the features to the top-left, implying they are Attractive.
In practice, there are three separate forms of flatlining that can be detected in Kano data:
- Flatlining in the functional data.
- Flatlining in the dysfunctional data.
- Flatlining in the categorization. That is, a person's data raw data may not contain any flatlining, but once their data is analyzed, it becomes apparent that the resulting categorization contains no discrimination at all.
Inconsistent data
Any respondent in the Questionable category has provided inconsistent data. The implication of this is that any other data they have provided will also be suspect. Thus, deleting the data from respondents who are in the questionable category for any of the features should cause the percentage of features in other categories to shift as well.
Implausible reverses
Where an attribute clearly has a benefit, if it is categorized as Reverse, it may be appropriate to delete the case from the data or filter it out from the Kano Model analysis. However, some caution is advised here. As discussed in Checking that Data is Not Impossible, it can be easy to be overzealous. Furthermore, the standard question formats for the Kato Model are arguably poorly written, which we would anticipate would lead to some poor-quality responses.
Example
The table below shows a categorization analysis for a smartwatch study. Around 10% of respondents are in the Questionable category for each feature.
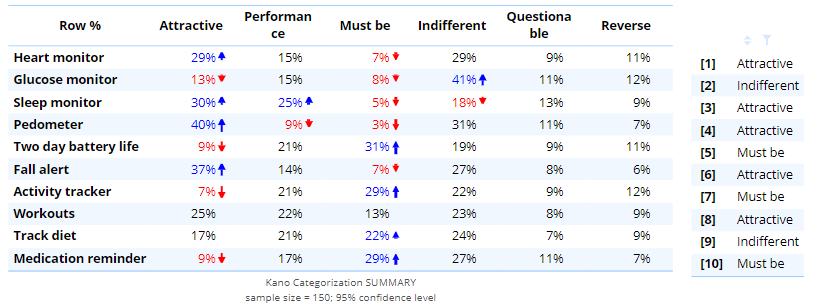
Data cleaning resulted in half of the sample being excluded. In ordinary circumstances, it would be considered problematic to remove so much of the sample for having poor quality data. However, with the Kano model, we are just deleting respondents we know muddy the results, so there is no real cost to such a large loss of sample size. That is, the data that is removed is essentially uninformative. Further, the conclusions do change as a result of the data cleaning. For example:
- Track diet has moved from Indifferent to Must be, and the difference is strong.
- Relativities between features change. Fall alert is behind Pedometer in terms of being Attractive with the unclean data but has moved to be the most attractive feature.
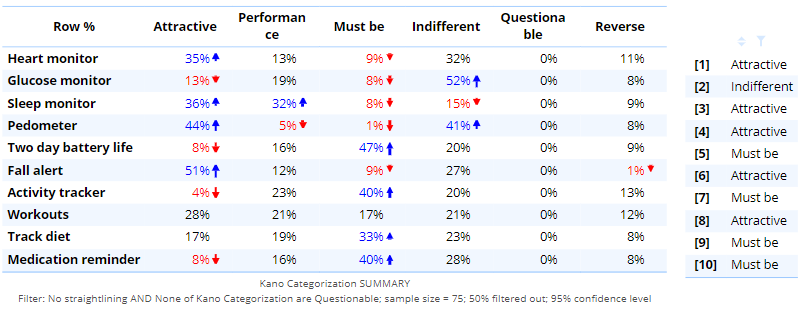
No attempt was made to clean the data based on implausible reverses.
Comments
0 comments
Please sign in to leave a comment.