
Text data can be the most informative data when investigating data integrity. When checking text data, we look for:
Text data can be the most informative data when performing data checking
Most other forms of data force the data to comply with rules (e.g., with well-managed data collection, there's no way for a person to indicate a negative age). Consequently, you are most likely to identify when data is fundamentally bad with text data.
The fix for serious problems in text data is usually to delete the case. Simply setting the poor data as missing is difficult to justify, as then you are hiding problems rather than addressing their root cause.
Missing data
Where a text variable contains no data but should contain data, this is a sign of a data integrity problem. Before deciding that it's a fundamental problem, it is helpful to check if:
- The field was optional.
- A sensible person could choose to leave it blank. It's not unknown for surveys, for example, to contain poorly worded questions that a respondent can reasonably decide not to waste time answering.
Nonsense responses
Nonsensical data is also an issue. As discussed in the previous point, sometimes text data has been obtained through ill-conceived data collection (e.g., poorly worded questions), so some leniency is appropriate. However, if the person has clearly given an answer that is just nonsense and cannot be justified by poor question wording, it is a sign that all of their data may be poor.
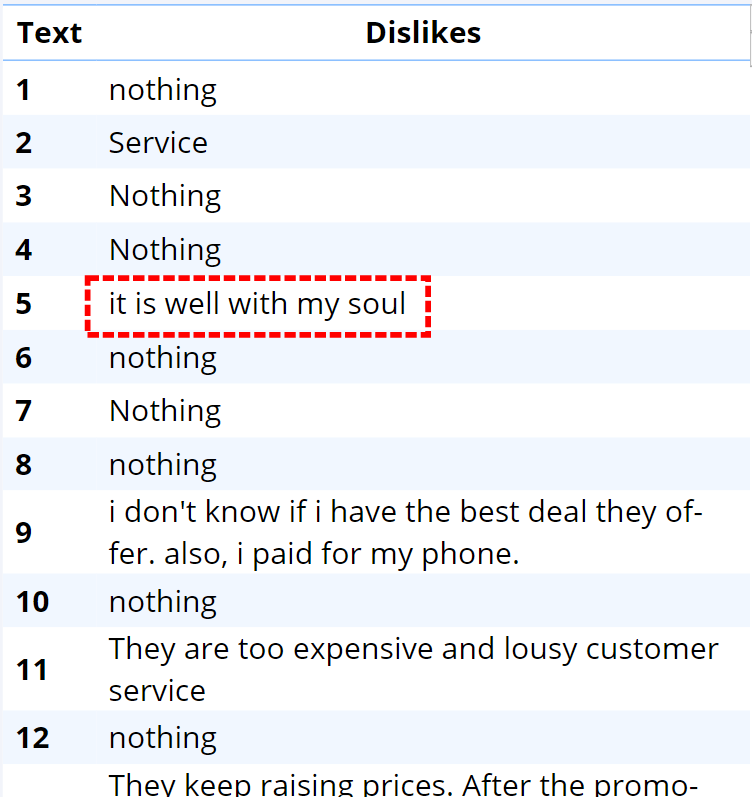
Duplicates
Occasionally, when data files are created, the same cases appear multiple times. This is a serious data integrity issue. One way of detecting this is to look for duplicate values in text fields. When doing this, keep in mind that it is common that shorter responses can be made by multiple people (e.g., nothing in the table above). A solution is to create a new variable that concatenates all the text variables into a single variable and examine it for duplicates.
Comments
0 comments
Please sign in to leave a comment.