
With numeric variables, histograms should be created to show the distribution of the variables when we:
- Look for implausible results.
- Check for multiple modes.
- Investigate skewness.
- Reduce bin size to see other patterns.
Histograms
The standard way of examining the distribution of numeric variables is to use histograms. The histogram below shows some data on the heights of people in centimeters.
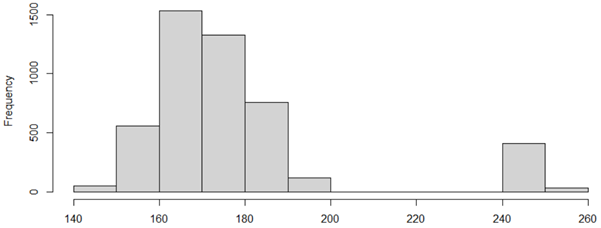
Looking for implausibly high or low values
Histograms make it easy to spot unusually high or low values (see Checking that Data is Not Impossible). Very few people are taller than 240 centimeters (7 feet and 10 inches), suggesting a data integrity issue revealed by the histogram.
When we have unusual values, an essential part of the data inspection process is concluding the cause of the missing values (see Checking and Understanding Missing Data). Without such conclusions, it's not possible to correct the problem. In the above example, the documentation reveals that missing values were recorded as 99 which, when converted to centimeters, becomes 250. The way to correct this data is to recode it as missing values.
Multiple bumps ("modes")
When viewing a histogram, multiple distinct bumps (mode) in the data can indicate a potential problem, as it occurs in the histogram above. When the histogram shows multiple bumps it typically means one of the following:
- The width of the columns (bins) of the histogram is not wide enough.
- There is a data integrity problem.
- There are multiple populations in the data.
Skews
The histogram below shows the number of text messages sent by a sample of cell phone users. The other chief pattern we can see is that the data is skewed, meaning that the data does not follow a nice symmetrical bell curve.
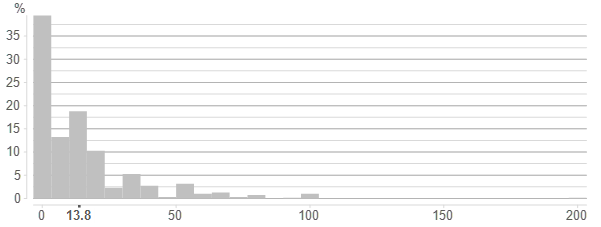
Skewness is extremely common in data. The normal distributions that appear in textbooks are much less common than skewed distributions in the real world. Skewness has two implications:
- A small number of observations will contribute heavily to the average. For example, if the data relates to consumption, we can conclude that a small number of people are responsible for the lion's share of consumption.
- It can mean that significance tests are less reliable.
With skewed data, it is often advisable to either cap, log, or categorize the data.
Reduce bin size
By default, most histograms tend to show a relatively small number of columns, such as in the example below. When the goal is to check data, it is advisable to increase the number of columns in the histograms (or, to use the jargon, increase the number of bins). The chart below allows us to see we have a data integrity problem known as shelving, whereby people have tended to provide data in round numbers. Of the spikes at 0, 10, 20, 30, 40, 50, 60, 70, 80, and 100, only the one at 0 is plausible.

Shelving is a particularly difficult problem to address. One implication is that if the values are merged into bands, multiples of 10 should not be used. For example, the value of 50 or more contains almost twice as many observations as More than 50.
Comments
0 comments
Please sign in to leave a comment.