
The distribution of a variable is the pattern made by its frequencies. With categorical data, the focus is usually on checking for small categories.
When examining a categorical variable, we typically want to look at a summary table and check the counts. We are typically looking for the following issues:
- Are any results surprising?
- Are there any smaller categories that need to be merged? There are a few different motives for merging categories:
- If the categories are very small, they are too small to be worth including.
- If the variable is a key profiling variable (e.g., age), we may want the categories to have a large enough sample size for meaningful comparisons.
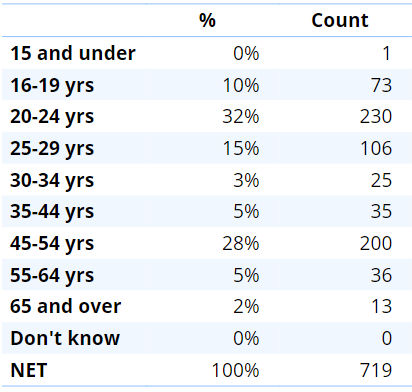
The table below shows the age data from a study of cell phones. The distribution (pattern) of the data suggests a data integrity issue. It's unlikely that any market would have so few people aged 30 - 34 and at the same time so many younger and older people. Nevertheless, sometimes it is necessary to analyze the data at hand, and if faced with data like the below, the fix is to merge the smaller categories into the adjacent larger categories.
Comments
0 comments
Please sign in to leave a comment.