
Categorical data can be converted to numeric data, and then analyzed as numeric data. This can greatly improve the efficiency of analysis by reducing the amount of data to be examined. The way that this is done differs by software. Care should be taken to assign non-ordered categories as missing and to align the values with the labels.
Improving the efficiency of analysis
Example 1: A single categorical variable with midpoint recoding
Consider the table below. It is hard to get a good read of this data due to the large number of categories.
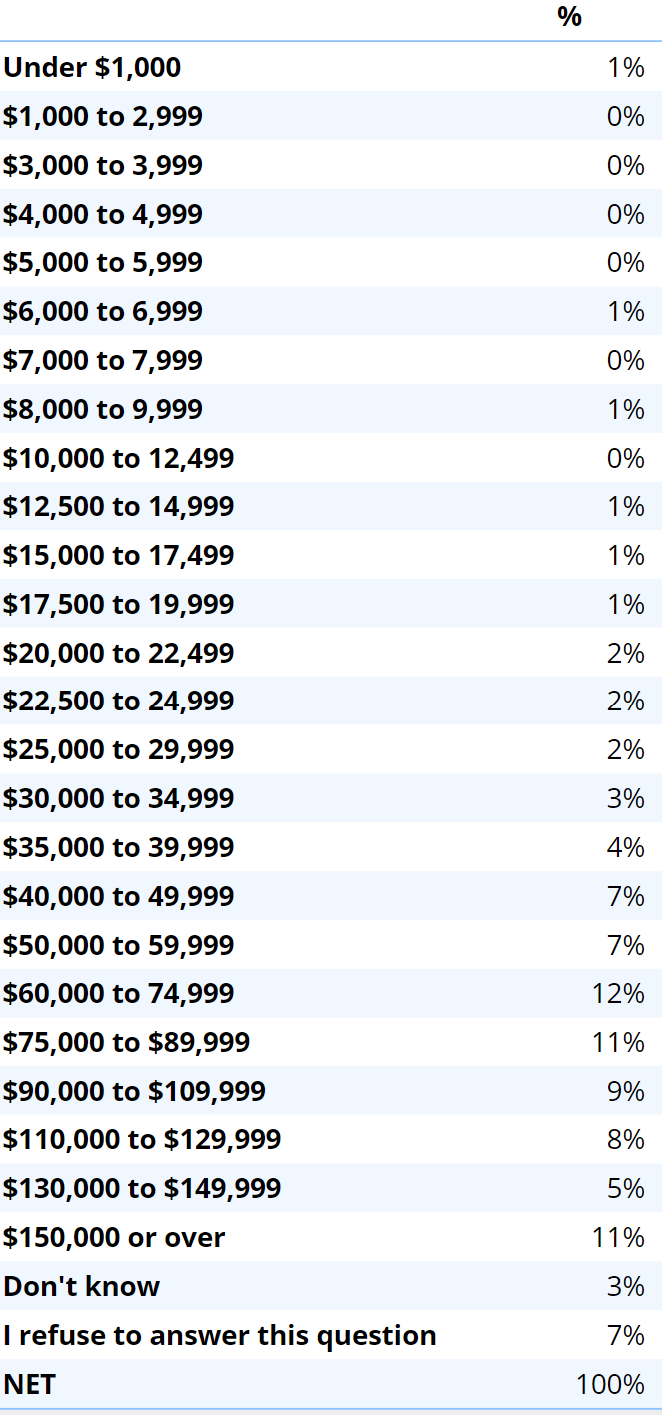
The table can be effectively summarized by:
- Converting it to be numeric.
- Recoding the values with values that reflect the meaning of the labels. In particular:
- 500 for Under $1,000
- 1999.5 for $1,000 to 2,999
- 3999.5 for $3,000 to 3,000
- ...
- 139999.5 for $130,000 to $149,999
- 159999.5 for $150,000 (note that this value has been chosen by looking at the difference between the previous category's midpoint and upper value).
- NA for Don't know
- NA for I refuse to answer this question
In this example, we are able to compress the results down to a single figure: an average income of $79,693.
More information about this approach is in Midpoint Recoding.
Example 2: A variable set of brand attitude
The table below shows attitudes towards six cola brands. Ignoring the NET column, it contains 30 percentages. (For a different approach to analyzing this data, see Converting Categorical Variables to Binary Variables.)
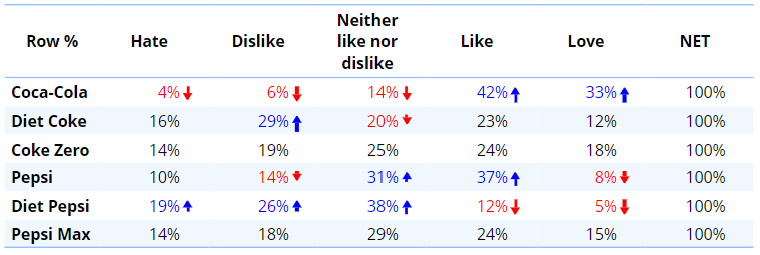
The table below shows the same data, except that rather than showing percentages, instead, it shows the average of the six variables, where Hate has been assigned a value of 1, Dislike a 2, Neither... a 3, Like a 4, and Love a 5. As the table only contains six numbers, it is much easier to interpret. We can easily see that Coca-Cola is most liked, and Diet Pepsi is least liked.
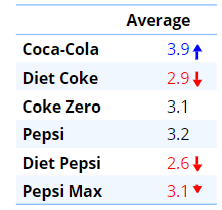
When we want to understand how the data relates to other data, the benefit of converting the data to numeric grows. Consider the case when we want to understand how the attitude to the cola brands differs by age, where age is in nine categories. A table showing all attitude categories by age would have 90 * 9 = 810 numbers to look at. It would take a long time to examine. However, the table below much more efficiently presents the information, allowing us to quickly spot the patterns.

The efficiency that is achieved by using numeric rather than categorical variables occurs on two levels:
- It is easier for the analyst, as there are fewer numbers to look at.
- The resulting analysis has more statistical power. If there is a pattern in the data, we are more likely to find it when we treat the data as numeric (provided that it is not a nonlinear pattern).
Different software packages approach this problem in very different ways
How to do this depends on the software being used to analyze the data. In the older software, such as SPSS statistics, there is only a weak concept of data type, and the user has to choose different analysis methods. That is, if you want to calculate averages, you use methods that calculate averages.
In more modern software, such as Q, Displayr, and R, the change is performed by changing the structure of the data. That is, you tell the software that the data is numeric, and it then automatically calculates averages instead of percentages.
Care should be taken to align labels with values
It is important when converting categorical variables to numeric, that the values chosen are sensible. Refer to Aligning Values With Labels for more information.
Comments
0 comments
Please sign in to leave a comment.